DDF and Dynamic Workload Balancing
Over in the dinosaur enclosure, we’ve been talking about Dynamic Workload Balancing and how it works. We think that there might be a missing link in the terminology, so read on and prepare to embrace “transaction routing”…
What is Dynamic Workload Balancing?
There are two levels of workload balancing implemented in client DDF connections:
- Connect-time, which is typically the DIVPA data sharing group contact point handing new connections off in a round-robin to each of the members
- Unit of Recovery (UR) level – dynamic workload balancing – which routes transactions in a balanced way to where the available capacity is in the data sharing group
Connect-time balancing tends to be unsatisfactory as once a thread has been established, it is stuck with that member until DDF is closed (quiesced or failure) or the client closes it. If the performance of the member is degraded for any reason, the client connections are still held there.
With dynamic workload balancing, DDF passes Workload Manager (WLM) capacity information back to the client periodically (anything from every 250ms to every 2 seconds, depending on activity). The client then seamlessly uses this information to route the following units of recovery in a balanced way to make best use of the available capacity.
In DB2 V8, the WLM information was just the available CPU capacity on the LPAR. From V10 this also included an available storage factor as well.
Sounds Good – What’s the Problem?
The problem is that WLM is typically involved twice in a client UR being executed, and this can cause confusion. There are two distinct activities which take place before the UR is executed in DB2:
- Transaction routing – this is where the client evaluates the WLM information that it has and decides which DB2 member it should send the transaction to.
- Workload service class assignment – this happens at the target LPAR where WLM qualifies the incoming transaction and assigns it the necessary performance characteristics.
It’s quite important not to get these mixed up, because things can become very confusing if one LPAR appears – to the DB2 client – to be over-committed.
How About an Example?
Consider an example where a four way data sharing group is running on four LPARs. Everything is going well until a large number of discretionary batch Omegamon reporting jobs are dropped into one of the LPARs. These will use the spare CPU capacity allowing the LPAR to run up to 100% in-use, but will be pre-empted by more important business workloads when they are started. What happens to the DDF clients? They will see zero capacity on that LPAR and route work away from it – even though, if the transaction had got there, WLM would have given them a higher importance and service class.
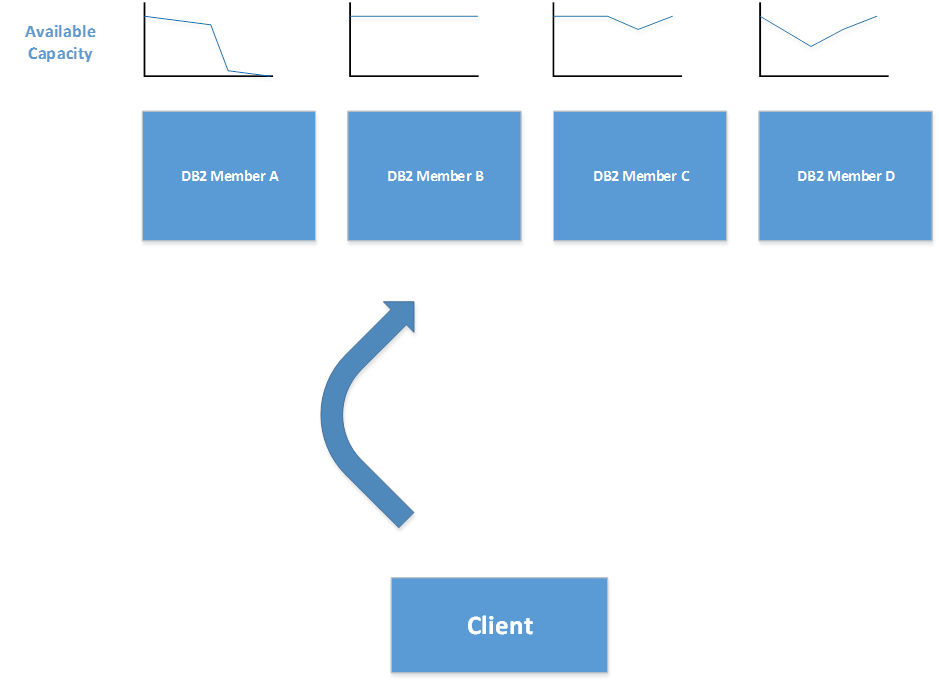
When this happens on one LPAR, it’s not too traumatic – a quarter of the capacity appears to disappear and the workload redistributes across the other members. Things can be a little more exciting if soaker jobs arrive on three out of four though.
Blimey! What Can I Do About This?
Stop right there. The first think to consider is: Is this actually a problem, or (hint) is DB2 doing what you want it to? The answer to this will, we suspect, largely depend on whether your business transactions continue to run and perform in a timely way. If they do, then – maybe – the answer is “Nothing” (working as designed). If not, then there is a second challenge that may require a release migration (anyone still on V8 out there?) to ensure that the connection and DBAT capacity and capability are present in sufficient numbers.
You certainly don’t want to have large numbers of connections queuing up waiting for a DBAT – or worse still, overflowing the queue and getting closed. How this queuing has evolved over the recent releases will be covered in the next blog post.
« Previous | Next »