Performance differences between upper-case (XQuery) and UPPER scalar function
I thought I’d share a recent performance issue I had with one of our customers. We’re in the Pre-Production testing stage of a project and our responsibility is a series of Stored Procedures to manage the INSERT, UPDATE and SELECT commands to be run against the database. As part of this testing we’ve had some feedback that the INSERT Procs are not performant and response times are unacceptable.
The way these procs work is that the application assembles a single XML document with all the required data and then calls the proc with that document as a single input parm. The proc then parses and validates all the elements passed in that XML document and executes half a dozen INSERT statements; one for each of the related tables in this Unit of Work.
I started looking at one of the procs by getting the explain plan back from the package. It’s got about 40 sections but the ones I homed in on where the INSERT statements. The Estimated Cost was in the 4-digit range but not as bad as some I’ve seen. What was a bit disturbing was that the access path showed the difference between the final INSERT statement and the preceding join, in terms of cumulative cost:
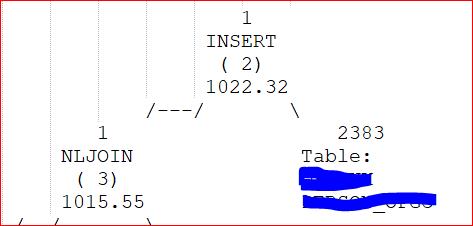
That would indicate that the actual INSERT only cost 7 timerons out of a total of 1,022. So where is the rest of the cost coming from?
The rest of the access path seems to be composed of many layers of these operations
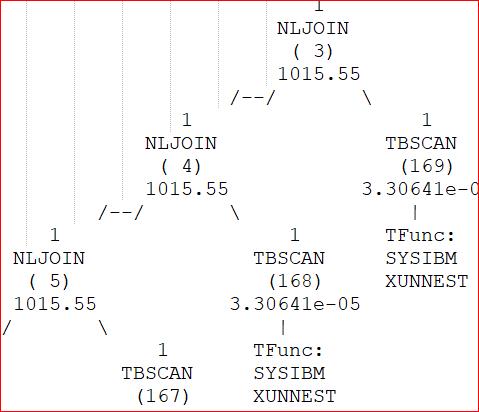
I’ve not been able to find anything specific about the SYSIBM.XUNNEST function but it led me to wonder if the use of the DB2 XQuery function upper-case() might have something to do with it. The procs have a requirement to translate all input to upper case; there are large volumes of mixed case data (e.g. names, addresses) and having them all stored as upper case makes subsequent searches easier to manage. To that end, every character-based element in the XML document is subject to an upper-case function within the XMLTABLE (old code on the left, changed code on the right):
Click image to enlarge

I removed all the upper-case functions and changed to the use of the UPPER scalar function:

The subsequent access path bears out the theory:
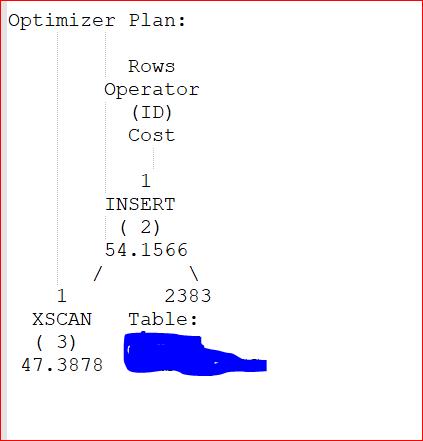
Estimated cost is down to 54 timerons from 1,022 and the graphical access path has a single layer. It would appear that the use of XQuery functions within a large document might be detrimental to performance and you should rely on good ole DB2 Functions to do the job.
If anyone has any comments and / or more information on what is going on with respect to XUNNEST functionality, I’d be glad to hear.
E-mail: Mark.Gillis@triton.co.uk
Mobile: +44 (0)7786 624704
It looks like the upper-case() function in the Xquery expressions prevents an optimization that otherwise allows all the Xquery expressions in the XMLTABLE function to be evaluated with a single pass through the document.
Hi Matthias. Do you think that might be something that will apply to any XML function we put in there? I’m wondering if we ought to let our client know that they should stick the DB2 functions for performance reasons