Pivoting and Unpivoting data with pureXML part 2
The previous blog Pivoting and Unpivoting data with pureXML I was looking at how to ‘unpivot’ data: take a string of values stored in a single VARCHAR column and present them as a set of single values. This one is examining the flip-side of the problem: where data that is really a single entity spans a number of rows and needs to be pivoted into a single entity to make sense.
Before I demonstrate how to use pureXML to accomplish this I need to own up to an omission on my part; when I ran this past my colleagues one of them asked ‘why not use LISTAGG’? It’s not a function I’m familiar with but I did some tests and, sure enough, you can get broadly the same results with simpler SQL if you use LISTAGG. There a couple of possible gotchas, but let me show you the original pureXML version and then I’ll show you the LISTAGG version for comparison and point out the gotchas. You can choose what suits you.
Let’s take a table which is used to store DDL, but which only has a VARCHAR(350) column in which to store the statements (if you think this sounds contrived, let me promise you, hand on heart, that this is based on an actual problem I’ve had to deal with on a client site. The data has been changed but the principle is the same).
The table is defined as

where the SQL_Command value (relabelled A_KEY) represents a single statement, SQL_SubString (relabelled B_KEY) is the sub-part of each command and the value that indicates the order for reassembling the command and the SQL_Text is, well, the SQL text itself. Take a look at a sub-set of rows in the table (the SQL_Text is chopped at 80 bytes to keep the display readable):
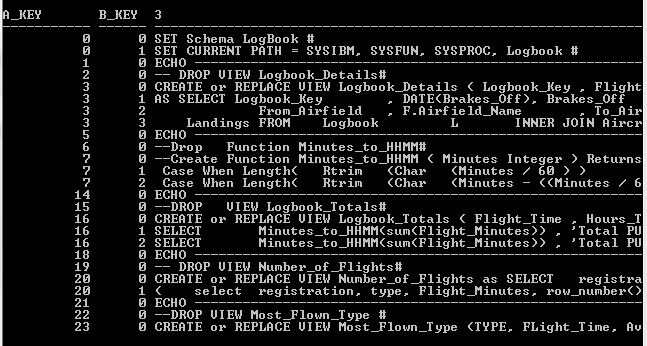
There are different types of statement in here but they’re mostly CREATE VIEW commands. If you look at SQL_COMMAND value 3, you can see it has SQL_SUBSTRING values of 0 to 3. It therefore has 4 fragments that need stitching back together. I want something that can take all the data in the SQL_LIBRARY table, pivot (or stitch) it into single entities and give me some output that I can execute.
This is the SQL I am going to use
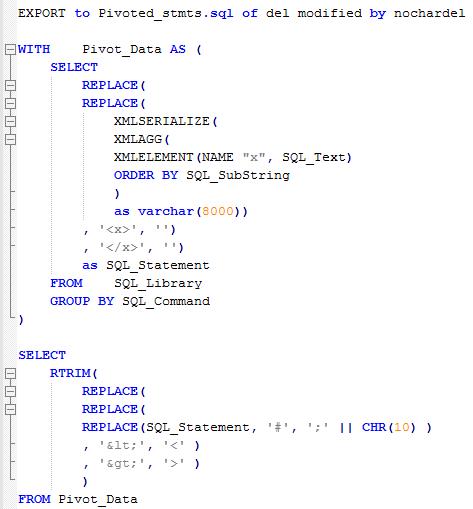
Let’s walk through this so we can see what’s going on. I will show the output at each stage but just use SQL_Command 3 rather than the whole data set to keep the blog size under control.
Here’s the full input data for SQL_Command 3

The first Common Table Expression uses three XML functions to create a single statement from each set of text within an SQL_Command value:
1) XMLELEMENT to get each of the SQL statements and wrap tags around it
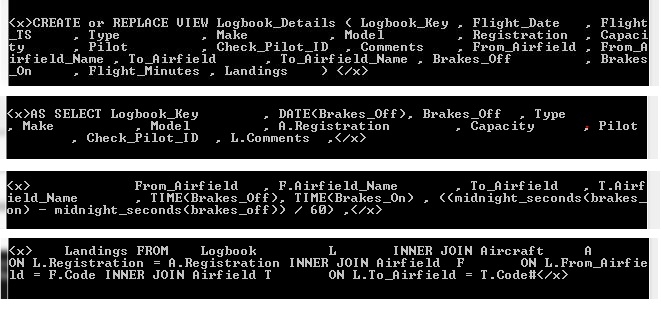
2) XMLAGG to return the set of XML elements as a single result (NB this is now a single row, and the correct order has been preserved by using the ORDER BY option in XMLAGG based on SQL_SubString )
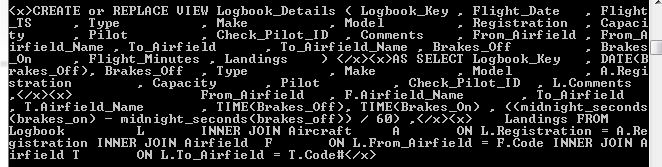
Gotcha : if the EXPORT statement is operational, the output file would contain this XDS reference rather than the SQL seen in the screen output above

3) XMLSERIALIZE to return the single result in text format: the results look identical but they are now in a VARCHAR column rather than an XML one
4) It then removes the tags (using REPLACE) leaving just an SQL string
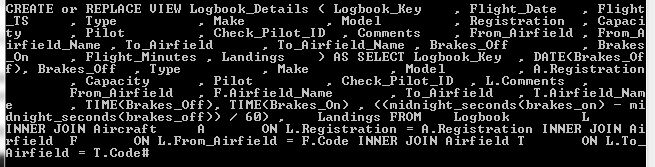
Once the CTE has processed the data into single SQL entities, the subsequent Select just does a bit of cleaning up:
5) The delimiter used in the SQL_Text (#) is replaced with semi-colon (;) and a line feed is appended
6) Gotcha : XML uses a special set of characters, notably &, < and > within its syntax. Therefore if you parse text as XML those values will be replaced:
- < with <
- > with >
- & with &
These values need to be restored for the SQL to be valid so this is done with a couple of REPLACE functions too. NB & is not handled here as it does not appear in this result set.
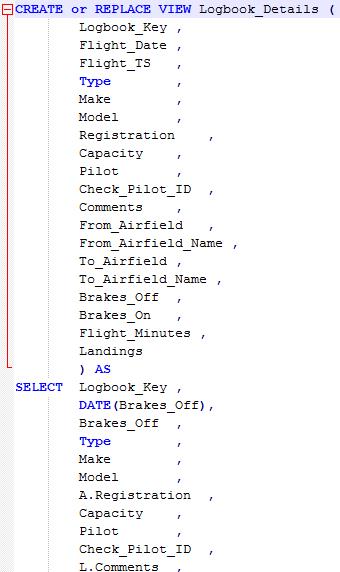
7) The EXPORT statement; well, that’s pretty straightforward. It’s using the NOCHARDEL option to prevent the statement being wrapped in quotes and DEL format to make sure it’s a flat text file that can serve as SQL to be input to the Command Line Processor, or whatever means we’re going to use to run the final query. The output file will have a single line for each command. It’s not very readable so I’ve edited to reintroduce some ‘sensible’ line breaks
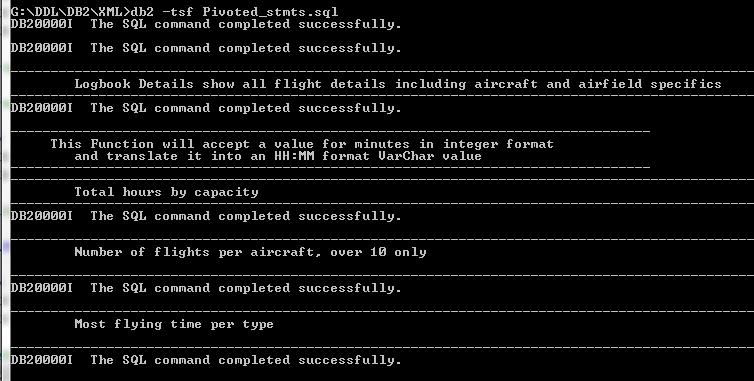
If I ran the entire contents through this process, rather than just SQL_Command 3, I would end up with a file containing 16 commands from the 25 rows stored in the original table. The exported SQL file can be executed as is, with no further editing, as all the relevant sub-commands have been pivoted into meaningful SQL statements.
You may not have exactly this problem, but any data spread over a number of rows can be handled in this way, using pureXML. I doubt if this is something that you’ll need every day of the week, but both the pivot and unpivot options are useful things to have in your tool-kit.
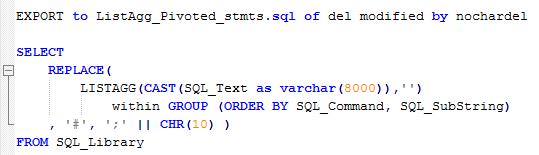
Now, I did say that this can be done using LISTAGG. The SQL is pretty straightforward
And the output can be executed as above, with the same results. The gotchas are
1)LISTAGG will need a temporary tablespace with a suitable page size (8K in this example)

That’s not the end of the world but it introduces an aspect to the solution that would involve some DBA input rather than just throwing it out there to your developers maybe
2) LISTAGG is also subject to limits on its output

3) LISTAGG was introduced with V9.7 FP4. There are still people out there who are on earlier releases (the client I alluded to at the start being one, hence my involvement with an XML solution) and, even if you are on a release of V9.7 that is post FixPack 4, you may still get an SQL0440N. Task a look at the word from IBM: https://www-01.ibm.com/support/docview.wss?uid=swg21588635
4) And, finally, the pureXML solution I showed will stitch the data into separate commands: the 25 rows of normalized data becoming 16 rows of normalized data. The LISTAGG statement will execute 1 row, with all the commands in it; but as a single entity. I don’t believe this is a problem as it can still be executed in the same way and with the same results and, once it’s in an editor like Notepad++ it is configured as one command per line in the script anyway.
So, there you have 2 options to tackle the problem; one pureXML and one using a simple function. Keep both in your toolbox for that day when it suddenly becomes an issue of paramount importance.
« Previous | Next »