Pivoting and Unpivoting data with pureXML
I am sometimes presented with data that, although stored in the relational database, still needs some ‘massaging’ to be meaningful. An issue that would fall into that category would be where a set of values has been stored in a string; in order for this to be usable I really need to “unpivot” it so that I have a result set composed of distinct values.
Let’s look at an example. Here is a simple table with a character group ID and a string of values stored as a VARCHAR(100).

The values are really integers; primary keys to another table and I want those available as a set of unique values.
In the past I have addressed this problem with recursive SQL and there’s nothing wrong with that, except that it is a bit cumbersome to maintain. If I wanted some SQL to render these strings of values as a result set of single keys, I’d need something like this (I’m just querying two of the smaller groups to avoid flooding the blog with results):

That does give the required result set
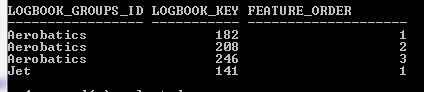
but it’s a tricky bit of SQL to maintain.
A better option might be to exploit the XML capabilities that come as part of the DB2 package anyway. A nice compact piece of SQL will cast the input string as an XML document and then exploit XMLTABLE to return the values as a results set
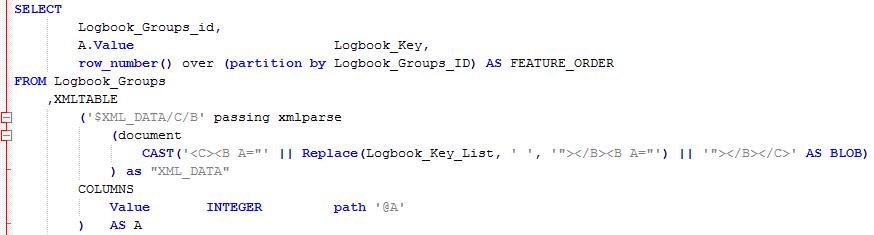
If this SQL is embedded in a view
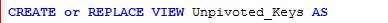
then the query can be executed against that to get the same result set

This query is, in my humble opinion, more intuitive and therefore easier to maintain. It also performs well when combined with other relational data. For instance, if the above query is used as the basis for a view (UNPIVOTED_KEYS) it can be combined with the detailed data from the source table to expand on the individual keys with enriched data
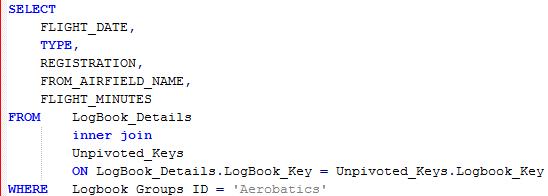

But what about the opposite problem? Imagine that some kind soul has decided to store a long and reasonably complex set of data across several rows and you need to collate or pivot it into a single entity? Well pureXML can help you out there too ….. but let’s take a look at that in the next blog.
« Previous | Next »