Recovering from corrupt DB2 Storage Group Control Files
Recently, we received a distress call from a client who was unable to access their production database and the data within. Client’s main aim was to recover the data from the database by any possible means.
The (short) description of the situation was:
-there are two DB2 instances on the server, one TEST and one PROD
-both instances are up and running
-TEST database is fully accessible
-the initial (activating) connection to the PROD database fails with “SQL0902C A system error occurred”, i.e. the PROD database cannot be activated nor accessed
The Culprits
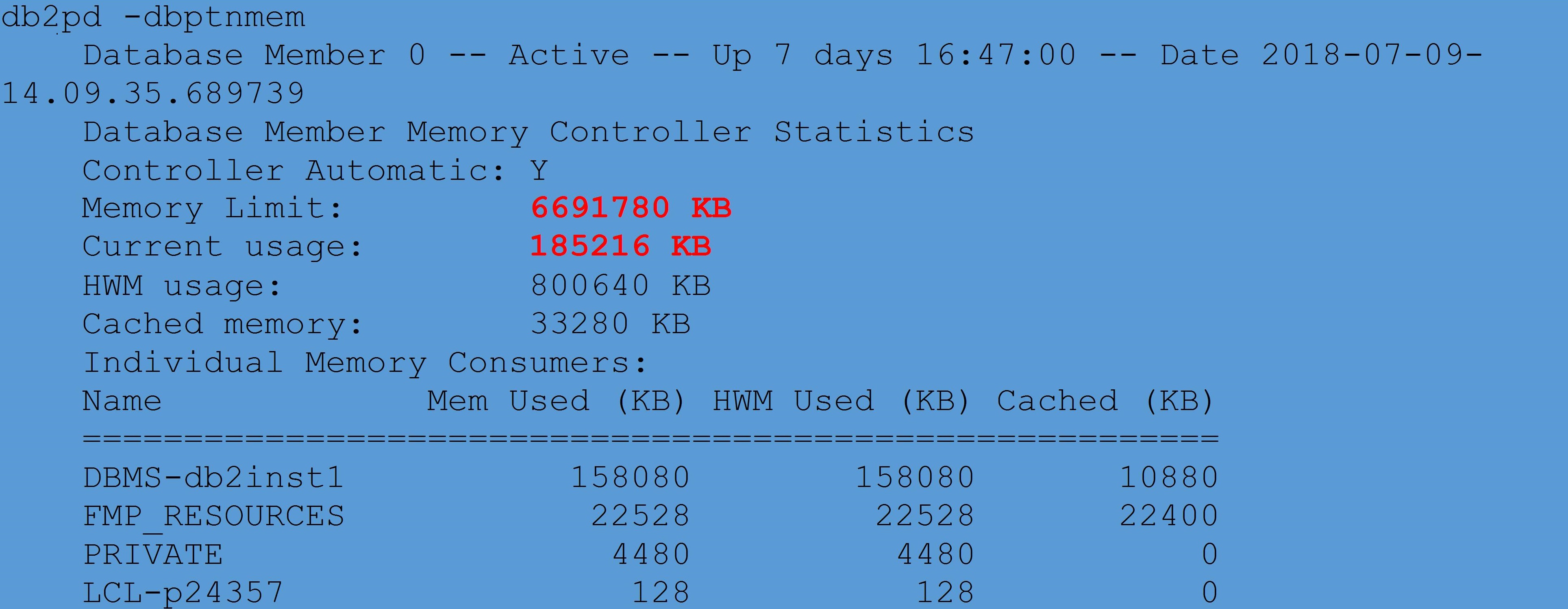
Our first suspicion was that the server might simply have ran out of resources, having to provide for two different DB2 instances and databases, but one look at the db2pd told us otherwise:
(click images to enlarge)
We next analysed the db2diag.log file, which provided more clues to the possible root cause of the problem:

As it appears, there seemed to have been a problem with the Storage Group control files. Error messages from the db2diag.log file indicated a possible corruption, but it was practically impossible to tell what exactly went wrong because no diagnostic tool wanted to work against this database (even db2dart was throwing errors).
While further discussing the whole situation with the client, we learned that the PROD database was functioning correctly, until the following command was executed:

Sometime after this command was (successfully) executed against the database, it suddenly crashed and couldn’t be reactivated thereafter.
Important thing to note here is that the client had not had the chance to create any objects (tablespaces) in this new storage group, nor to rebalance the existing tablespaces across it, so the new storage group was effectively still inactive. To make matters even more confusing, the same storage group was created in the TEST database and there were no issues!
To exacerbate the chances of fulfilling the primary requirement (recover the data), the database was in a circular logging regime, with no recent backups available, so there was no possibility at all of recovering the data by performing a restore/rollforward operation.
To the rescue
Our next attempt at resurrecting the PROD database was based around the idea to bring the database back to its state before the new storage group was created. In other words, we wanted to scrap the new storage group, which seemed to be the root cause of the problem, in favour of reactivating the database.
This wouldn’t get in the way of recovering the data from the database, as the new storage had not been put in use (there were no tablespaces created/moved into it and therefore it contained no data).
A very good hint how this can be done came from the following IBM Support article:
https://www-01.ibm.com/support/docview.wss?uid=swg21682091
Solutions (answers) 1 and 2 were not usable in our case, as already explained, but solution 3 looked promising, so this is what we have done next, in short:
- Created a new and identical (but empty) PROD database on another server by issuing a set of create commands, which at the end contained the exact same storage structure as the real PROD database (minus the latest and inactive storage group, as explained above).
-for this purpose, the client provided us with a clone of the PROD server with identical disk resources
-mercifully, a DB2LOOK file was available, containing commands to create the database and all required objects (storage groups, tablespaces, bufferpools, etc.) - Took the two SQLSGF files of the new database (located in the database directory) and copied them to the same directory of the real PROD database, replacing the corrupt ones
After that, the database was activated and connected to successfully:
 Problem solved, data saved, hooray!
Problem solved, data saved, hooray!
Conclusion
It remains unclear what exactly happened that caused the corruption of the SG control files, as there were no clues in the db2diag.log related to it and no other diagnostic tools worked or offered more info.
However, the database was brought back to life by simply replacing the corrupted SG files with a set of fresh (and not corrupted) ones.
Lesson Learned #1:
-having a recent OS backup image can significantly speed up the recovery, by restoring the required files directly from it
Lesson Learned #2:
-always with no exceptions take backups of your production databases on a regular basis – always, always, always!
Lesson Learned #3:
-have a recent db2look file available, containing the current definitions of all database objects
Authors: Damir Wilder and Iqbal Goralwalla
Leave a Reply