ZLOAD – Mid-Range Data LOAD into DB2 for z/OS
Introduction
Most customers will have to deliver external data to DB2 for z/OS from time to time. For some, this will be a daily feed of volume data from clients and business partners, whilst for others it might be smaller mid-range generated test data.
All will have faced the usual challenges delivering data from mid-range platforms:
- Code page challenges – when FTP’ing between two different code pages, you need to use a translation table. You will need to understand which ones are available, and might need to build one yourself. DB2 will let you LOAD data in ASCII – so long as it’s the right codepage – or UNICODE, so this can be mitigated.
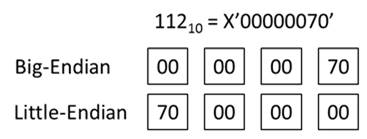
- Binary data format challenges. The zSeries processor is Big-Endian, i.e. it writes the most significant byte of a number first. Mid-range platforms (except for Java) are Little-Endian, writing their least significant byte of a number first. E.g.
- Physically moving the data to z/OS requires reading the whole source file, pushing it over the network and then writing all of that data to a z/OS dataset.
By writing the data in comma delimited format (CSV), numerics are in human readable (as opposed to binary) format, so codepage translation can be used on the whole file:

Moving the data to a z/OS dataset isn’t really a big deal if it’s a couple of rows of data, but what’s the impact if we’re talking about a supplier data refresh with 10 million rows?
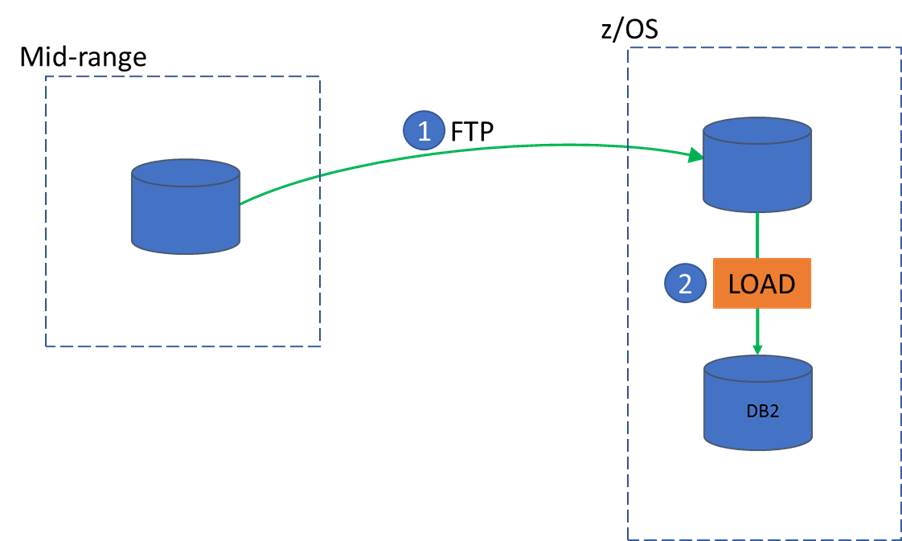
- The FTP client reads the whole file and passes it over the network to z/OS where it is reformatted (typically into VB format) and stored in a z/OS dataset
- The LOAD utility is run, which reads and formats the data so that it can write it into a DB2 pageset
From an elapsed time point of view, the LOAD utility has to wait until the file transfer has completed before it can start.
ZLOAD
In a nutshell, what ZLOAD does is remove the intermediary z/OS dataset. It creates a network pipe to push the data down from the client, then starts the LOAD utility (under the DSNUTILU stored procedure) at the other end. This means that we only read the file once, and we only write the data once straight into the target DB2 table.
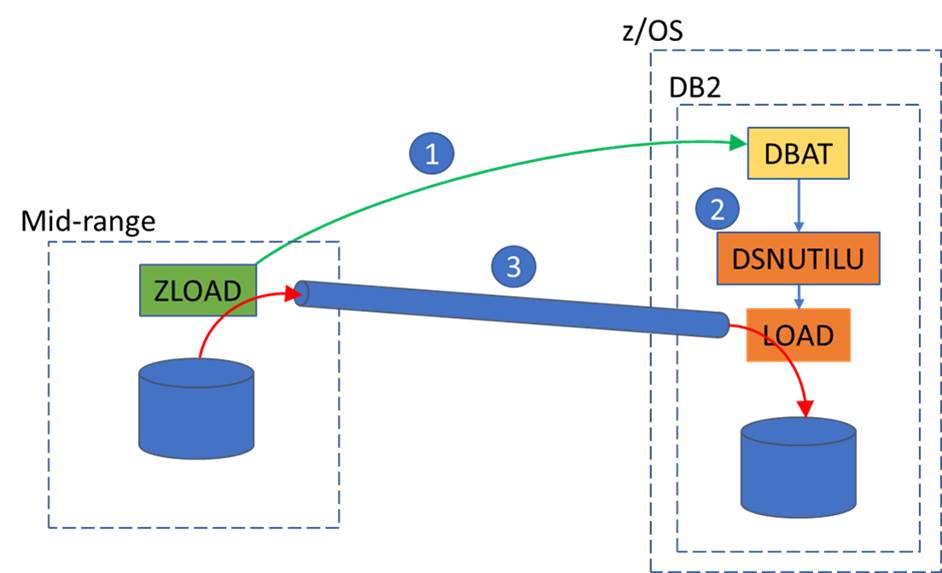
- Using an existing connection, ZLOAD drives the DBAT to…
- …start the DSNUTILU stored procedure, running the supplied LOAD command
- The mid-range file is piped directly to LOAD as the data file
A couple of things to note here:
- The pipe passes data in binary mode – i.e. no codepage translation
- The elapsed time saved is at least the amount of time it would have taken to write the z/OS staging dataset in the traditional method.
What’s Required to Use This?
There are a couple of pre-reqs:
- DB2 V12 – the support is a new (GA) feature in DB2 for z/OS V12
- DB2 LUW at V11.1 Fix Pack 1 via:
- DB2 LUW V11.1 Fix Pack 1, or DB2 Connect V11.1 Fix Pack 1, available from:
https://www-01.ibm.com/support/docview.wss?uid=swg24043113 - Data Server Driver 11.1 Fix Pack 1, available from:
https://www-01.ibm.com/support/docview.wss?uid=swg24043166 - DB2 JDBC driver (available as part of the packages linked, above) 3.72.24, as reported by:
- DB2 LUW V11.1 Fix Pack 1, or DB2 Connect V11.1 Fix Pack 1, available from:
java com.ibm.db2.jcc.DB2Jcc -version
The feature can be driven as a CLP command (ZLOAD), or a JDBC connection function (zLoad).
Example Code
In the following sections there are some coding examples. These are available in full on GitHub:
https://github.com/db2dinosaur/db2-zload-sample
ZLOAD Command Format
The ZLOAD CLP command looks like this:

Where:
datafilenameis the local (mid-range) data file – more on the required format for this belowutilityidis the optional utility ID to give the LOAD. If not specified, ZLOAD makes one up using the current Julian date and time:- “ZLOAD”jjjjhhmmssth where
- jjj = Julian day (# of the day within the year)
- hh = hour (24 hour clock)
- mm = minute
- ss = second
- th = tenths and hundredths
- eg. ZLOAD06210425492 for a ZLOAD command run on the 3rd March (2017) at 10:42:54.92
- “ZLOAD”jjjjhhmmssth where
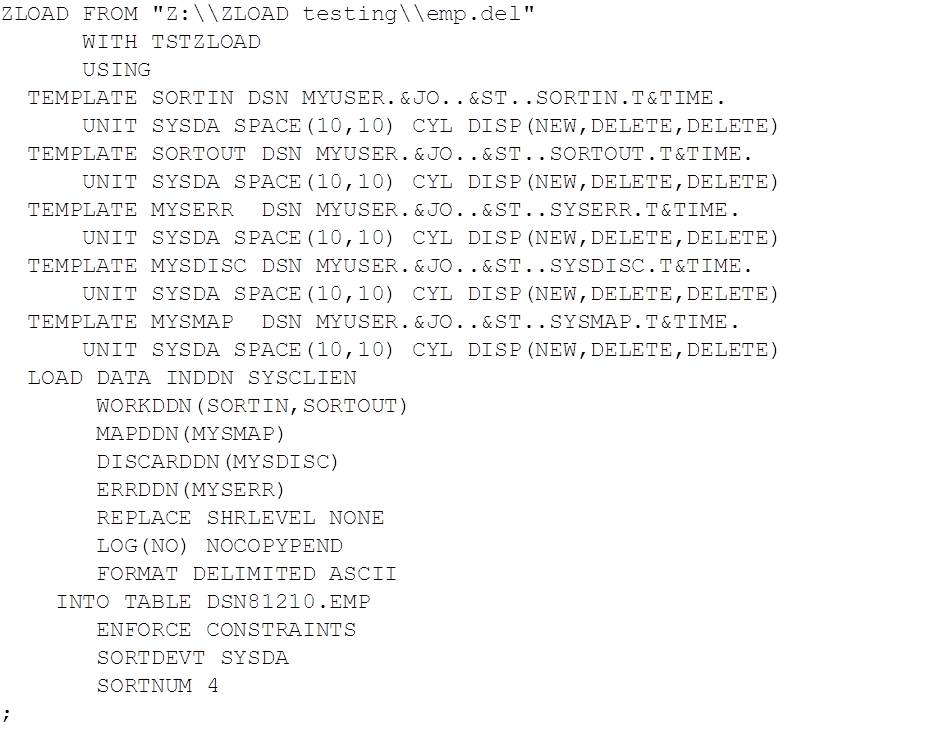
msgfilenameis the fully qualified filename for ZLOAD to write DSNUTILU responses to. If not specified, they are returned to stdout.utilstmtis the LOAD utility statement. This can include TEMPLATE statements but MUST set the INDD to SYSCLIEN to tell LOAD to read from the supplied pipe.
In the following example, the LOAD data file was generated by running an UNLOAD DELIMITED utility and then ASCII FTP downloaded in block mode – more on this in the LOAD Data File Format section, below:

The zloademp.txt file looks like this:
JDBC zLoad Call Format
JDBC can also be used to drive the ZLOAD function. The feature is part of the DB2Connection interface, and is lightly documented in the DB2 for z/OS V12 Java Programming Guide:

The parameters have the same meaning as in the ZLOAD CLP command above.
The interface also provides access to the returned RC and messages through the LoadResult object:

The following is some Java code which drives zLoad to reload the same data file as in the ZLOAD command example above:

LOAD Data File Format
The LOAD data file has to be in a special format to be compatible with ZLOAD. This isn’t very clearly documented at the moment, but needs to be in Block Mode format. This is a reference to an Internet Engineering Task Force (IETF) Request For Comment (RFC) number 959, which can be viewed here:
https://www.ietf.org/rfc/rfc959.txt
The required format is discussed in section 3.4.2 (BLOCK MODE), and is outlined here as well.
Each record or row of data delivered requires a three byte header – referred to as the Record Descriptor – made up of a single byte Type and a two-byte (Big-Endian) record data length:

Type (T) can have one of the following values according to RFC959:
- 128 (x’80’) = End of data block is EOR (end of record) – i.e. more records follow this one
- 64 (x’40’) = End of data block is EOF (end of file) – i.e. this is the last record in the file
- 32 (x’20’) = Suspected data errors in the block (not used by ZLOAD)
- 16 (x’10’) = Data block is a restart marker (not currently used by ZLOAD)
When reformatting CSV (comma delimited) data into this form, don’t forget that the length field has to be Big-Endian. This is easy to do with Java, which keeps its binary data in Big-Endian format. The following Java code reads emp.csv record by record, calculating the two byte length and then writing the type byte, length and record to the output file:
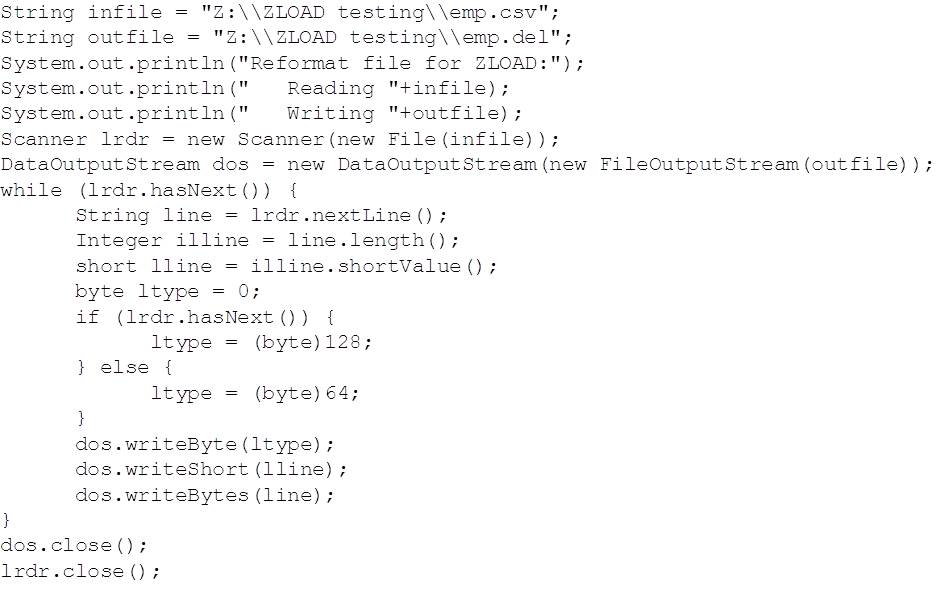
If you generated your data on z/OS and wanted to use FTP to create the mid-range file in the right format, you can use block mode on the download to achieve this. In the following example, I’m downloading the UNLOAD DELIMITED output (created as EBCIDC) to my Windows test box:

Surprise (Undocumented) Reason Codes
There are some new DB2 reason codes which may be returned in messages to the mid-range driver that have not made it into the documentation yet. The ones that I’m aware of are:
- 00D31301 = Invalid record descriptor. I saw this a lot in my testing until I got the information from RFC959 about the data file format. It means that the type code is invalid.
- 00D31302 = Block length error, and is caused by the file ending before the indicated length. Probably we haven’t got the length field correct, but it might mean that the record descriptor is missing as well and we were just lucky!
No Utility Restart
At the time of writing, there is no support for restarting failed utilities. If you have a large file to load, and an unreliable network connection, you might want to either sort out the reliability issue, or use traditional methods!
Conclusions
Whilst the documentation is not (at the time of writing) as strong as we are used to from IBM, the ZLOAD function itself is impressive. Both DevOps and volume data delivery / ETL teams will make effective use of this, significantly cutting the time to deliver data in comparison with traditional methods.
« Previous | Next »